| Resources | |||||
|---|---|---|---|---|---|
| GCP | Splitting and merging with code | ||||
| cp-algo | Description and code | ||||
| Algorithm Tutorial | Code and diagrams | ||||
| Benq | Description of Split and Merge | ||||
| CF | Proof of time complexity for merging treaps | ||||
Treaps
Like a regular binary search tree, treaps contain keys that can be inserted, erased, and searched for in . However, regular binary search trees suffer from imbalancing, which causes the tree to have up to an depth and blows up the time complexity.
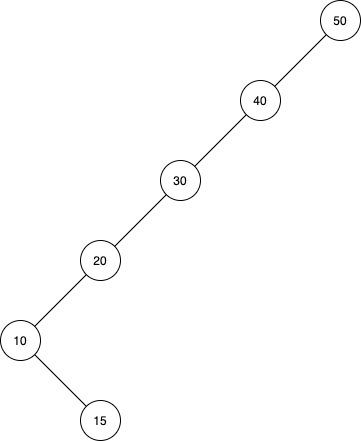
A treap is a randomized binary search tree that stores two numbers in its nodes: a value and a priority. The values of a treap will satisfy the binary search tree property (where all the nodes in the left subtree are strictly smaller than the current node and all the nodes in the right subtree are strictly greater than the current node), and the priorities will satisfy the heap property (where all descendants of a node will have smaller or equal priorities).
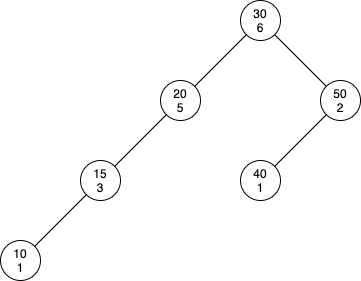
Treaps have two main operations: splitting and merging. Other operations like insert, erase, and searching can be implemented in terms of these operations.
Splitting
The split method takes in a pointer to the root of a treap and
a value , and returns two treaps denoted as and
. Like the name suggests, it splits the tree such that all nodes
in have keys less than or equal to and all nodes in
have keys greater than .
We can now implement it recursively. Let the left child of a node be denoted as and the right child as .
- If , then both the root and the left subtree belong to . We now consider a call to
spliton and note its results as and . Finally, contains and . - If , then both the root and the right subtree belong to . We now consider a call to
spliton and note its results as and . Finally, contains and .
Merging
The merge method inverts the split method by taking in two treaps
and and returns a single treap that has the
nodes of both treaps. It works under the assumption that all keys
are strictly smaller than all keys .
Furthermore, we need to merge these two treaps such that the resultant treap
still satisfies the max heap property.
We root the resultant treap at the root node that has the higher priority, and
recursively call merge on the other tree and the corresponding subtree of the
chosen tree.
Implementation
#include <stdlib.h>struct Node {// the value and priority of the node respectivelyint val, pri;// pointer to left and right child (NULL means no child)Node *left, *right;Node(int val) : val(val), pri(rand()), left(NULL), right(NULL){};} *root;
For speed / memory, use arrays of fixed size rather than pointers.
Implicit Treaps
Focus Problem – try your best to solve this problem before continuing!
In their most basic form, treaps are not very useful (languages like C++ and Java already have a built-in self-balancing binary tree that is much more efficient than treaps). However, with implicit treaps, we can efficiently perform operations on a regular array in fashion similar to segment trees and fenwick trees. The following operations are supported by implicit treaps:
- Insert an element at position
- Delete the element at position
- Performing interval queries (sum, min, max, etc.)
- Perform interval updates (add, set, reverse, etc.)
The key behind implicit treaps lies in their name. We will use the index of the node to be its key. Because maintaining this value explicitly will result in up to values to be updated per insertion/deletion, we will keep this value implicitly.
The index of a node is equal to the number of nodes less than it. It is important to note that these nodes can occur both in the left subtree of the current node as well as the node's ancestors and the left subtree of its ancestors.
Note that in an implicit treap, the merge function is largely unchanged because it does not depend on the key. In the split operation we go from the root down, so we simply maintain a running count of the size left subtree.
An implementation of the split operation may look something like:
void split(Node *treap, Node *&left, Node *&right, int val, int add = 0) {if (!treap) {left = right = NULL;return;}int cur_size = add + size(treap->left); // implicit keyif (cur_size < val) {split(treap->right, treap->right, right, val, add + 1 + size(treap->left));left = treap;
In the split operation, because we are always comparing to , we can simply eliminate the parameter by subtracting from each time. Our new code looks like:
void split(Node *treap, Node *&left, Node *&right, int val) {if (!treap) {left = right = NULL;return;}if (size(treap->left) < val) {split(treap->right, treap->right, right, val - size(treap->left) - 1);left = treap;} else {split(treap->left, left, treap->left, val);right = treap;}treap->size = 1 + size(treap->left) + size(treap->right);}
Implementation
struct Node {int val;int weight, size;Node *left, *right;Node(int c) : val(c), weight(rand()), size(1), left(NULL), right(NULL) {}} *root;int size(Node *treap) { return treap ? treap->size : 0; }void split(Node *treap, Node *&left, Node *&right, int val) {
Solution
We will use implicit treaps to represent the array. For each operation, divide it into two phases: cut and paste. For the cut phase, we split the array into three parts: , , and . This can be accomplished using two split operations. For the paste phase, we can rearrange the sections such that we merge them in the order . This can be done using two merge operations.
#include <bits/stdc++.h>using namespace std;struct Node {char val;int weight, size;Node *left, *right;Node(char c) : val(c), weight(rand()), size(1), left(NULL), right(NULL) {}} *root;
Implicit treaps are also capable of updates/removals of elements, range queries, range updates, and range reversals.
Focus Problem – try your best to solve this problem before continuing!
- Insert can be done with one split and two merges: We split the array between the index we want to insert, create a new node with the corresponding value, and merge the three sections together.
- Delete can be done with two splits and one merge: We split the array into three parts before and after the index, and merge the two parts together.
- Range queries can be performed by maintaining additional data in each node. We update this data whenever we update .
- Range updates can be performed by maintaining a lazy tag in each node (as in lazy propagation). When splitting or merging, we push these tags downwards and perform the corresponding operation.
- Range reversals can be performed by maintaining a lazy
reversedtag in each node. When splitting or merging, we first swap the node's left and right children, then push the tag down.
Implementation
This code solves the above problem, but also provides a generalizable template for any range update/query.
Time complexity:
#include <bits/stdc++.h>using namespace std;using ll = long long;Code Snippet: ModInt class (Click to expand)struct Line { // linear function wx + bmint w = 1, b = 0;mint operator()(mint x) { return w * x + b; }Line operator()(Line f) { return Line{w * f.w, w * f.b + b}; }
Problems
| Status | Source | Problem Name | Difficulty | Tags | ||
|---|---|---|---|---|---|---|
| CSES | Easy | Show TagsTreap | ||||
| CSES | Easy | Show TagsTreap | ||||
| POI | Normal | Show TagsTreap | ||||
| NOI | Normal | Show TagsTreap | ||||
| Old Gold | Normal | Show TagsTreap | ||||
| CSA | Normal | Show TagsTreap | ||||
| HE | Normal | Show TagsTreap | ||||
| IOI | Hard | Show Tags2DRQ, Sparse SegTree, Treap | ||||
Module Progress:
Join the USACO Forum!
Stuck on a problem, or don't understand a module? Join the USACO Forum and get help from other competitive programmers!